Ključna riječ IDENTITY je svojstvo u SQL Serveru. Kada je stupac tablice definiran svojstvom identiteta, njegova će vrijednost biti automatski generirana inkrementalna vrijednost . Ovu vrijednost automatski kreira poslužitelj. Stoga ne možemo ručno unijeti vrijednost u stupac identiteta kao korisnik. Stoga, ako označimo stupac kao identitet, SQL Server će ga popuniti na način automatskog povećanja.
Sintaksa
Sljedeća je sintaksa za ilustraciju upotrebe svojstva IDENTITY u SQL Serveru:
IDENTITY[(seed, increment)]
Gore navedeni parametri sintakse objašnjeni su u nastavku:
Razumimo ovaj koncept kroz jednostavan primjer.
Pretpostavimo da imamo ' Student ' stol, i želimo Studentska iskaznica generirati automatski. Imamo početna studentska iskaznica 10 i želite ga povećati za 1 sa svakim novim ID-om. U ovom scenariju moraju se definirati sljedeće vrijednosti.
Sjeme: 10
Povećanje: 1
CREATE TABLE Student ( StudentID INT IDENTITY(10, 1) PRIMARY KEY NOT NULL, )
NAPOMENA: Samo jedan identifikacijski stupac dopušten je po tablici u SQL Serveru.
Primjer IDENTITETA SQL poslužitelja
Hajde da shvatimo kako možemo koristiti svojstvo identiteta u tablici. Svojstvo identiteta u stupcu može se postaviti ili kada se kreira nova tablica ili nakon što je kreirana. Ovdje ćemo vidjeti oba slučaja s primjerima.
Svojstvo IDENTITY s novom tablicom
Sljedeća izjava će stvoriti novu tablicu sa svojstvom identiteta u navedenoj bazi podataka:
CREATE TABLE person ( PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL, Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Zatim ćemo u ovu tablicu umetnuti novi redak s IZLAZ klauzula da vidite automatski generirani ID osobe:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.PersonID VALUES('Sara Jackson', 'HR', 'Female');
Izvršavanje ovog upita prikazat će donji izlaz:
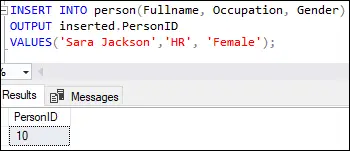
Ovaj izlaz pokazuje da je prvi redak umetnut s vrijednošću deset u ID osobe stupac kako je navedeno u stupcu identiteta definicije tablice.
Umetnimo još jedan red u stol osoba kao ispod:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.* VALUES('Mark Boucher', 'Cricketer', 'Male'), ('Josh Phillip', 'Writer', 'Male');
Ovaj upit će vratiti sljedeći izlaz:

Ovaj izlaz pokazuje da je drugi red umetnut s vrijednošću 11, a treći red s vrijednošću 12 u stupcu PersonID.
Svojstvo IDENTITY s postojećom tablicom
Objasnit ćemo ovaj koncept tako da prvo izbrišemo gornju tablicu i stvorimo ih bez svojstva identiteta. Izvršite donju naredbu da ispustite tablicu:
DROP TABLE person;
Zatim ćemo izraditi tablicu pomoću upita u nastavku:
CREATE TABLE person ( Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Ako želimo dodati novi stupac sa svojstvom identiteta u postojeću tablicu, moramo koristiti naredbu ALTER. Upit u nastavku će dodati PersonID kao stupac identiteta u tablici osoba:
ALTER TABLE person ADD PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL;
Izričito dodavanje vrijednosti u stupac identiteta
Ako dodamo novi red u gornju tablicu eksplicitnim navođenjem vrijednosti stupca identiteta, SQL Server će izbaciti pogrešku. Pogledajte donji upit:
INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 13);
Izvršenje ovog upita će prikazati sljedeću pogrešku:

Da bismo eksplicitno umetnuli vrijednost stupca identiteta, moramo prvo postaviti vrijednost IDENTITY_INSERT na ON. Zatim izvedite operaciju umetanja za dodavanje novog reda u tablicu i zatim postavite vrijednost IDENTITY_INSERT na ISKLJUČENO. Pogledajte donju skriptu koda:
SET IDENTITY_INSERT person ON /*INSERT VALUE*/ INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 14); SET IDENTITY_INSERT person OFF SELECT * FROM person;
IDENTITY_INSERT ON omogućuje korisnicima da stave podatke u stupce identiteta, dok IDENTITY_INSERT ISKLJUČEN sprječava ih da dodaju vrijednost ovom stupcu.
Izvršavanje skripte koda prikazat će donji izlaz gdje možemo vidjeti da je PersonID s vrijednošću 14 uspješno umetnut.

Funkcija IDENTITETA
SQL Server pruža neke funkcije identiteta za rad sa IDENTITY stupcima u tablici. Ove funkcije identiteta navedene su u nastavku:
- Funkcija @@IDENTITY
- Funkcija SCOPE_IDENTITY().
- IDENT_CURRENT funkcija
- Funkcija IDENTITETA
Pogledajmo funkcije IDENTITY s nekoliko primjera.
Funkcija @@IDENTITY
@@IDENTITY sistemski je definirana funkcija koja prikazuje posljednju vrijednost identiteta (maksimalna iskorištena vrijednost identiteta) stvorena u tablici za stupac IDENTITY u istoj sesiji. Ovaj stupac funkcije vraća vrijednost identiteta generiranu naredbom nakon umetanja novog unosa u tablicu. Vraća a NULL vrijednost kada izvršavamo upit koji ne stvara IDENTITY vrijednosti. Uvijek radi u okviru trenutne sesije. Ne može se koristiti na daljinu.
Primjer
Pretpostavimo da je trenutna najveća vrijednost identiteta u tablici osoba 13. Sada ćemo dodati jedan zapis u istoj sesiji koji povećava vrijednost identiteta za jedan. Zatim ćemo upotrijebiti funkciju @@IDENTITY da dobijemo posljednju vrijednost identiteta stvorenu u istoj sesiji.
Ovdje je potpuna skripta koda:
SELECT MAX(PersonID) AS maxidentity FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Brian Lara', 'Cricket', 'Male'); SELECT @@IDENTITY;
Izvršavanje skripte vratit će sljedeći izlaz gdje možemo vidjeti da je najveća korištena vrijednost identiteta 14.

Funkcija SCOPE_IDENTITY().
SCOPE_IDENTITY() je sistemski definirana funkcija za prikazati najnoviju vrijednost identiteta u tablici pod trenutnim opsegom. Ovaj opseg može biti modul, okidač, funkcija ili pohranjena procedura. Slična je funkciji @@IDENTITY(), osim što ova funkcija ima samo ograničen opseg. Funkcija SCOPE_IDENTITY vraća NULL ako je izvršimo prije operacije umetanja koja generira vrijednost u istom opsegu.
Primjer
Kôd u nastavku koristi funkcije @@IDENTITY i SCOPE_IDENTITY() u istoj sesiji. Ovaj će primjer prvo prikazati posljednju vrijednost identiteta, a zatim umetnuti jedan redak u tablicu. Zatim izvršava obje funkcije identiteta.
SELECT MAX(PersonID) AS maxid FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Jennifer Winset', 'Actoress', 'Female'); SELECT SCOPE_IDENTITY(); SELECT @@IDENTITY;
Izvršenje koda prikazat će istu vrijednost u trenutnoj sesiji i sličan opseg. Pogledajte izlaznu sliku u nastavku:

Sada ćemo na primjeru vidjeti kako se obje funkcije razlikuju. Prvo ćemo stvoriti dvije tablice s imenima podaci_zaposlenika i odjelu koristeći donju izjavu:
CREATE TABLE employee_data ( emp_id INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL ) GO CREATE TABLE department ( department_id INT IDENTITY(100, 5) PRIMARY KEY, department_name VARCHAR(20) NULL );
Zatim stvaramo okidač INSERT na tablici employee_data. Ovaj se okidač poziva za umetanje retka u tablicu odjela svaki put kada umetnemo redak u tablicu Emploee_data.
Upit u nastavku stvara okidač za umetanje zadane vrijednosti 'TO' u tablici odjela na svakom upitu za umetanje u tablicu podatci o zaposleniku:
glavna metoda java
CREATE TRIGGER Insert_Department ON employee_data FOR INSERT AS BEGIN INSERT INTO department VALUES ('IT') END;
Nakon stvaranja okidača, umetnut ćemo jedan zapis u tablicu employee_data i vidjeti izlaz funkcija @@IDENTITY i SCOPE_IDENTITY().
INSERT INTO employee_data VALUES ('John Mathew');
Izvršenje upita će dodati jedan redak u tablicu podatci o zaposleniku i generirati vrijednost identiteta u istoj sesiji. Nakon što se upit za umetanje izvrši u tablici employee_data, on automatski poziva okidač za dodavanje jednog retka u tablicu odjela. Početna vrijednost identiteta je 1 za Emploee_data i 100 za tablicu odjela.
Konačno, izvršavamo donje izjave koje prikazuju izlaz 100 za funkciju SELECT @@IDENTITY i 1 za funkciju SCOPE_IDENTITY jer vraćaju vrijednost identiteta samo u istom opsegu.
SELECT MAX(emp_id) FROM employee_data SELECT MAX(department_id) FROM department SELECT @@IDENTITY SELECT SCOPE_IDENTITY()
Evo rezultata:

IDENT_CURRENT() funkcija
IDENT_CURRENT je sistemski definirana funkcija za prikazati najnoviju vrijednost IDENTITY generiran za danu tablicu pod bilo kojom vezom. Ova funkcija ne uzima u obzir opseg SQL upita koji stvara vrijednost identiteta. Ova funkcija zahtijeva naziv tablice za koju želimo dobiti vrijednost identiteta.
Primjer
To možemo razumjeti ako prvo otvorimo dva prozora za povezivanje. Ubacit ćemo jedan zapis u prvi prozor koji generira vrijednost identiteta 15 u tablici osoba. Zatim možemo provjeriti ovu vrijednost identiteta u drugom prozoru veze gdje možemo vidjeti isti izlaz. Ovdje je cijeli kod:
1st Connection Window INSERT INTO person(Fullname, Occupation, Gender) VALUES('John Doe', 'Engineer', 'Male'); GO SELECT MAX(PersonID) AS maxid FROM person; 2nd Connection Window SELECT MAX(PersonID) AS maxid FROM person; GO SELECT IDENT_CURRENT('person') AS identity_value;
Izvršavanje gornjih kodova u dva različita prozora prikazat će istu vrijednost identiteta.

Funkcija IDENTITY().
Funkcija IDENTITY() sistemski je definirana funkcija koristi se za umetanje stupca identiteta u novu tablicu . Ova se funkcija razlikuje od svojstva IDENTITY koje koristimo s naredbama CREATE TABLE i ALTER TABLE. Ovu funkciju možemo koristiti samo u naredbi SELECT INTO, koja se koristi prilikom prijenosa podataka iz jedne tablice u drugu.
Sljedeća sintaksa ilustrira upotrebu ove funkcije u SQL Serveru:
IDENTITY (data_type , seed , increment) AS column_name
Ako izvorna tablica ima stupac IDENTITY, tablica formirana naredbom SELECT INTO ga nasljeđuje prema zadanim postavkama. Na primjer , prethodno smo kreirali osobu tablice sa stupcem identiteta. Pretpostavimo da kreiramo novu tablicu koja nasljeđuje tablicu osoba pomoću naredbi SELECT INTO s funkcijom IDENTITY(). U tom slučaju dobit ćemo pogrešku jer izvorna tablica već ima stupac identiteta. Pogledajte donji upit:
SELECT IDENTITY(INT, 100, 2) AS NEW_ID, PersonID, Fullname, Occupation, Gender INTO person_info FROM person;
Izvršenje gornje izjave vratit će sljedeću poruku o pogrešci:

Kreirajmo novu tablicu bez svojstva identiteta pomoću donje izjave:
CREATE TABLE student_data ( roll_no INT PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL )
Zatim kopirajte ovu tablicu pomoću izjave SELECT INTO uključujući funkciju IDENTITY na sljedeći način:
SELECT IDENTITY(INT, 100, 1) AS student_id, roll_no, fullname INTO temp_data FROM student_data;
Nakon što se izjava izvrši, možemo je provjeriti pomoću sp_help naredba koja prikazuje svojstva tablice.

Možete vidjeti stupac IDENTITET u ISKUŠLJIV svojstva prema navedenim uvjetima.
Ako koristimo ovu funkciju s naredbom SELECT, SQL Server će kroz sljedeću poruku o pogrešci:
Poruka 177, razina 15, stanje 1, redak 2. Funkcija IDENTITY može se koristiti samo kada izjava SELECT ima klauzulu INTO.
Ponovno korištenje IDENTITY vrijednosti
Ne možemo ponovno koristiti vrijednosti identiteta u tablici SQL Servera. Kada izbrišemo bilo koji redak iz tablice stupca identiteta, stvorit će se praznina u stupcu identiteta. Također, SQL Server će stvoriti prazninu kada umetnemo novi red u stupac identiteta, a izjava je neuspješna ili vraćena. Razmak označava da su vrijednosti identiteta izgubljene i da se ne mogu ponovno generirati u stupcu IDENTITY.
Razmotrite primjer u nastavku da biste ga praktično razumjeli. Već imamo tablicu osoba koja sadrži sljedeće podatke:

Zatim ćemo stvoriti još dvije tablice pod nazivom 'položaj' , i ' položaj_osobe ' pomoću sljedeće izjave:
CREATE TABLE POSITION ( PositionID INT IDENTITY (1, 1) PRIMARY KEY, Position_name VARCHAR (255) NOT NULL ); CREATE TABLE person_position ( PersonID INT, PositionID INT, PRIMARY KEY (PersonID, PositionID), FOREIGN KEY (PersonID) REFERENCES person (PersonID), FOREIGN KEY (PositionID) REFERENCES POSITION (PositionID) );
Zatim pokušavamo umetnuti novi zapis u tablicu person i dodijeliti im položaj dodavanjem novog retka u tablicu person_position. To ćemo učiniti korištenjem izjave o transakciji kao u nastavku:
BEGIN TRANSACTION BEGIN TRY -- insert a new row into the person table INSERT INTO person (Fullname, Occupation, Gender) VALUES('Joan Smith', 'Manager', 'Male'); -- assign a position to a new person INSERT INTO person_position (PersonID, PositionID) VALUES(@@IDENTITY, 10); END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION; END CATCH IF @@TRANCOUNT > 0 COMMIT TRANSACTION;
Gornja skripta koda transakcije uspješno izvršava prvu naredbu umetanja. Ali druga izjava nije uspjela jer nije bilo pozicije s ID-om deset u tablici pozicija. Stoga je cijela transakcija poništena.
Budući da imamo maksimalnu vrijednost identiteta u stupcu PersonID 16, prvi izraz za umetanje potrošio je vrijednost identiteta 17, a zatim je transakcija vraćena. Stoga, ako u tablicu Person umetnemo sljedeći redak, sljedeća vrijednost identiteta bit će 18. Izvršite naredbu u nastavku:
INSERT INTO person(Fullname, Occupation, Gender) VALUES('Peter Drucker',' Writer', 'Female');
Nakon ponovne provjere tablice osoba, vidimo da novododani zapis sadrži vrijednost identiteta 18.

Dva IDENTITY stupca u jednoj tablici
Tehnički, nije moguće stvoriti dva stupca identiteta u jednoj tablici. Ako to učinimo, SQL Server izbacuje pogrešku. Pogledajte sljedeći upit:
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, ID2 INT IDENTITY (100, 1) NOT NULL )
Kada izvršimo ovaj kod, vidjet ćemo sljedeću grešku:

Međutim, možemo stvoriti dva stupca identiteta u jednoj tablici pomoću izračunatog stupca. Sljedeći upit stvara tablicu s izračunatim stupcem koji koristi izvorni stupac identiteta i smanjuje ga za 1.
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, SecondID AS 10000-ID1, Descriptions VARCHAR(60) )
Zatim ćemo dodati neke podatke u ovu tablicu pomoću donje naredbe:
INSERT INTO TwoIdentityTable (Descriptions) VALUES ('Javatpoint provides best educational tutorials'), ('www.javatpoint.com')
Na kraju provjeravamo podatke tablice pomoću naredbe SELECT. Vraća sljedeći izlaz:

Na slici možemo vidjeti kako stupac SecondID djeluje kao drugi stupac identiteta, smanjujući se za deset od početne vrijednosti od 9990.
Zablude u stupcu IDENTITY SQL Servera
DBA korisnik ima mnogo pogrešnih predodžbi o stupcima identiteta SQL Servera. Slijedi popis najčešćih zabluda u vezi stupaca identiteta koji bi se mogli vidjeti:
Stupac IDENTITY je JEDINSTVEN: Prema službenoj dokumentaciji SQL Servera, svojstvo identiteta ne može jamčiti da je vrijednost stupca jedinstvena. Moramo koristiti PRIMARY KEY, UNIQUE ograničenje ili UNIQUE indeks kako bismo nametnuli jedinstvenost stupca.
Stupac IDENTITY generira uzastopne brojeve: Službena dokumentacija jasno navodi da se dodijeljene vrijednosti u stupcu identiteta mogu izgubiti nakon kvara baze podataka ili ponovnog pokretanja poslužitelja. To može uzrokovati praznine u vrijednosti identiteta tijekom umetanja. Praznina se također može stvoriti kada izbrišemo vrijednost iz tablice ili se izjava umetanja vrati natrag. Vrijednosti koje stvaraju praznine ne mogu se dalje koristiti.
Stupac IDENTITY ne može automatski generirati postojeće vrijednosti: Nije moguće da stupac identiteta automatski generira postojeće vrijednosti sve dok se svojstvo identiteta ponovno ne postavi pomoću naredbe DBCC CHECKIDENT. Omogućuje nam da prilagodimo početnu vrijednost (početnu vrijednost retka) svojstva identiteta. Nakon izvođenja ove naredbe, SQL Server neće provjeravati novostvorene vrijednosti koje su već prisutne u tablici ili ne.
Stupac IDENTITET kao PRIMARNI KLJUČ dovoljan je za identifikaciju reda: Ako primarni ključ sadrži stupac identiteta u tablici bez ikakvih drugih jedinstvenih ograničenja, stupac može pohraniti duplicirane vrijednosti i spriječiti jedinstvenost stupca. Kao što znamo, primarni ključ ne može pohraniti duple vrijednosti, ali stupac identiteta može pohraniti duplikate; preporuča se ne koristiti svojstvo primarnog ključa i identiteta u istom stupcu.
Upotreba pogrešnog alata za vraćanje vrijednosti identiteta nakon umetanja: Također je uobičajena pogrešna predodžba o nesvjesnosti razlika između funkcija @@IDENTITY, SCOPE_IDENTITY(), IDENT_CURRENT i IDENTITY() kako bi se vrijednost identiteta izravno umetnula iz izjave koju smo upravo izvršili.
Razlika između SEKVENCE i IDENTITETA
Koristimo i SEQUENCE i IDENTITY za generiranje automatskih brojeva. Međutim, ima neke razlike, a glavna razlika je u tome što identitet ovisi o tablici, dok sekvenca nije. Sažmimo njihove razlike u tablični oblik:
| IDENTITET | SLIJED |
|---|---|
| Svojstvo identiteta koristi se za određenu tablicu i ne može se dijeliti s drugim tablicama. | DBA definira objekt niza koji se može dijeliti između više tablica jer je neovisan o tablici. |
| Ovo svojstvo automatski generira vrijednosti svaki put kada se na tablici izvrši izjava za umetanje. | Koristi klauzulu NEXT VALUE FOR za generiranje sljedeće vrijednosti za objekt niza. |
| SQL Server ne vraća vrijednost stupca svojstva identiteta na početnu vrijednost. | SQL Server može poništiti vrijednost za objekt niza. |
| Ne možemo postaviti maksimalnu vrijednost za svojstvo identiteta. | Možemo postaviti maksimalnu vrijednost za objekt niza. |
| Predstavljen je u SQL Serveru 2000. | Predstavljen je u SQL Serveru 2012. |
| Ovo svojstvo ne može generirati vrijednost identiteta u opadajućem redoslijedu. | Može generirati vrijednosti u opadajućem redoslijedu. |
Zaključak
Ovaj će članak dati potpuni pregled svojstva IDENTITY u SQL Serveru. Ovdje smo naučili kako i kada se koristi svojstvo identiteta, njegove različite funkcije, zablude i kako se razlikuje od niza.