Grupiranje ili analiza klastera je tehnika strojnog učenja koja grupira neoznačeni skup podataka. Može se definirati kao 'Način grupiranja podatkovnih točaka u različite klastere koji se sastoje od sličnih podatkovnih točaka. Predmeti s mogućim sličnostima ostaju u skupini koja ima manje ili nimalo sličnosti s drugom skupinom.'
To čini pronalaženjem sličnih uzoraka u neoznačenom skupu podataka kao što su oblik, veličina, boja, ponašanje itd., te ih dijeli prema prisutnosti i odsutnosti tih sličnih uzoraka.
To je učenje bez nadzora metoda, stoga algoritmu nije omogućen nadzor i on se bavi neoznačenim skupom podataka.
Nakon primjene ove tehnike grupiranja, svaki klaster ili grupa dobiva ID klastera. ML sustav može koristiti ovaj ID za pojednostavljenje obrade velikih i složenih skupova podataka.
tipovi binarnog stabla
Tehnika klasteriranja se obično koristi za statistička analiza podataka.
Napomena: Grupiranje je negdje slično algoritam klasifikacije , ali razlika je u vrsti skupa podataka koji koristimo. U klasifikaciji radimo s označenim skupom podataka, dok u grupiranju radimo s neoznačenim skupom podataka.
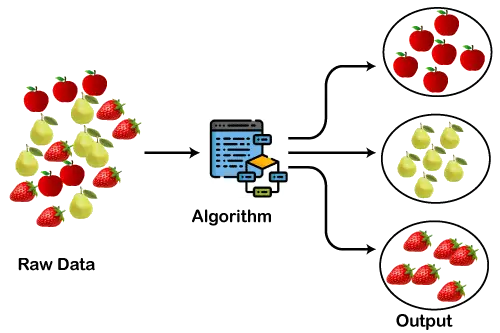
Primjer : Razumimo tehniku grupiranja na primjeru trgovačkog centra iz stvarnog svijeta: kada posjetimo bilo koji trgovački centar, možemo primijetiti da su stvari slične upotrebe grupirane zajedno. Kao što su majice grupirane u jednom odjeljku, a hlače su u drugim odjeljcima, slično tome, u odjeljcima s povrćem, jabuke, banane, mango, itd., grupirani su u zasebne odjeljke, tako da možemo lako pronaći stvari. Tehnika klasteriranja također radi na isti način. Drugi primjeri klasteriranja su grupiranje dokumenata prema temi.
Tehnika klasteriranja može se široko koristiti u raznim zadacima. Neke od najčešćih upotreba ove tehnike su:
- Segmentacija tržišta
- Statistička analiza podataka
- Analiza društvenih mreža
- Segmentacija slike
- Otkrivanje anomalija itd.
Osim ove opće uporabe, koristi ga Amazon u svom sustavu preporuka za pružanje preporuka prema prethodnom pretraživanju proizvoda. Netflix također koristi ovu tehniku da preporuči filmove i web-serije svojim korisnicima prema povijesti gledanja.
Donji dijagram objašnjava rad algoritma klasteriranja. Vidimo da je različito voće podijeljeno u nekoliko skupina sa sličnim svojstvima.
Vrste metoda klasteriranja
Metode klasteriranja općenito se dijele na Tvrdo grupiranje (točka podataka pripada samo jednoj grupi) i Meko grupiranje (podatkovne točke mogu pripadati i drugoj grupi). Ali postoje i drugi različiti pristupi klasteriranju. Ispod su glavne metode klasteriranja koje se koriste u strojnom učenju:
javascript onload skripta
Particioniranje klasteriranja
To je vrsta klasteriranja koja dijeli podatke u nehijerarhijske skupine. Također je poznat kao metoda temeljena na centroidu . Najčešći primjer particioniranja klastera je K-Means algoritam klasteriranja .
U ovoj vrsti, skup podataka je podijeljen u skup od k grupa, gdje se K koristi za definiranje broja unaprijed definiranih grupa. Središte klastera je kreirano na takav način da je udaljenost između podatkovnih točaka jednog klastera minimalna u usporedbi sa težištem drugog klastera.
selen

Grupiranje temeljeno na gustoći
Metoda klasteriranja temeljena na gustoći povezuje područja visoke gustoće u klastere, a distribucije proizvoljnog oblika formiraju se sve dok je gusto područje moguće povezati. Ovaj algoritam to čini identificiranjem različitih klastera u skupu podataka i povezuje područja visoke gustoće u klastere. Gusta područja u prostoru podataka međusobno su podijeljena rjeđim područjima.
Ovi se algoritmi mogu suočiti s poteškoćama u grupiranju podatkovnih točaka ako skup podataka ima različite gustoće i visoke dimenzije.

Klasteriranje temeljeno na modelu distribucije
U metodi klasteriranja temeljenoj na modelu distribucije, podaci se dijele na temelju vjerojatnosti pripadnosti skupa podataka određenoj distribuciji. Grupiranje se vrši uz pretpostavku nekih zajedničkih distribucija Gaussova distribucija .
Primjer ove vrste je Algoritam klasteriranja očekivanja-maksimizacije koji koristi Gaussove modele mješavine (GMM).

Hijerarhijsko grupiranje
Hijerarhijsko grupiranje u klastere može se koristiti kao alternativa za particionirano klasteriranje budući da ne postoji zahtjev za unaprijed određivanjem broja klastera koji će se stvoriti. U ovoj tehnici, skup podataka je podijeljen u klastere kako bi se stvorila struktura poput stabla, koja se također naziva a dendrogram . Opažanja ili bilo koji broj klastera mogu se odabrati rezanjem stabla na ispravnoj razini. Najčešći primjer ove metode je Aglomerativni hijerarhijski algoritam .

Neizrazito grupiranje
Neizrazito klasteriranje je vrsta meke metode u kojoj podatkovni objekt može pripadati više od jedne grupe ili klastera. Svaki skup podataka ima skup koeficijenata članstva, koji ovise o stupnju članstva u klasteru. Algoritam neizrazitih C-srednjih vrijednosti je primjer ove vrste klasteriranja; ponekad je poznat i kao algoritam neizrazitih k-srednjih vrijednosti.
Algoritmi klasteriranja
Algoritmi klasteriranja mogu se podijeliti na temelju njihovih modela koji su gore objašnjeni. Objavljeni su različiti tipovi algoritama klasteriranja, ali samo se nekoliko njih uobičajeno koristi. Algoritam klasteriranja temelji se na vrsti podataka koje koristimo. Na primjer, neki algoritmi trebaju pogoditi broj klastera u danom skupu podataka, dok neki moraju pronaći minimalnu udaljenost između promatranja skupa podataka.
Ovdje uglavnom raspravljamo o popularnim algoritmima klasteriranja koji se široko koriste u strojnom učenju:
struktura u strukturi podataka
Primjene klasteriranja
Ispod su neke općenito poznate primjene tehnike klasteriranja u strojnom učenju: